Optimization strategies
- Klaas Andries de Graaf
- Kostis Pristouris
- Kurt Junghanns
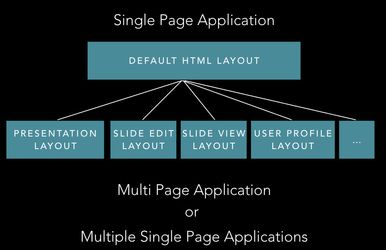
Splitting layout
- multi-page application → in components/defaultHTMLlayout.js → based on URL load certain libraries (e.g. CKeditor for visiting URL /edit)
- we can have a generic layout inherited by other layout if needed (e.g. ui intl libraries or shim libs need to be reused in most of the other layouts).
- multiple single-page applications → standalone aplication. E.g. presentation layout (reveal.js is large), slide edit layout (CKeditor = 600kb, Latex_ams.. libary = 500kb, ), slide view, user profile layout, etc... In practice → separate github repot + is separate application → has own server.js/client.js/etc...
- multiple single-page applications → Better for scalability
- multi-page application → better for user loading (only load libraries when necessary, based on URL/page visit)
- Presentation mode - standalone/multiple single-page applications - do not need to load fluxible, etc.. (single page application). Needs to load reveal.js and Latex_ams.. libary and maybe some SVG/diagram libraries, semantic UI)
- exam mode (
- user profile
- slide edit layout → multipage → part of platform → on loading /edit also load ckeditor, Latex_ams.. libary and some SVG/diagram libraries
Based on presentation (general-optimization.pdf) on optimization by Ali Khalili during Hackathon V3.0
 |
|
|
|---|---|---|

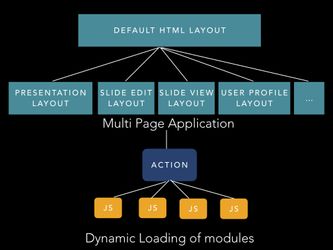
Dynamic/lazy loading of modules
→ action → select j.s. file . use ES6 require.ensure - Darya Tarasowa - interesting in applying - related to multi-language UI.
- Is complicated
- Is a bit old and only webpack feature, replaced with import() (as a function) / System.import() → https://webpack.js.org/guides/migrating/#code-splitting-with-es2015
- Is good for when other developers want to work on something → we give bundle with component, action, js. files/libraries
Optimise Current libraries
(see webpack visualiser: https://platform.experimental.slidewiki.org/public/js/stats.html) → check npm packages
- replace with another library (e.g. lodash is using 20% of our vendor.bundle.js code, maybe it can be replaced by a simpler one), or
- use own functions
Server Side Rendering (SSR) Insights
Description of the flow
The page is initially always rendered server-side. This means:
- a react + flux session is initiated and executed
- all needed actions are executed (waiting for responses, adding results to stores, rerendering, ...)
- if everything is ready and nothing is pending anymore, the page gets serialised to a valid html document, that is delivered to the browser
- listed libs in the DefaultHTMLTemplate are downloaded at the browser (not as of the SSR process)
For https://slidewiki.org/deck/82 , this takes about 25.86s and the file is about 5MB large (compressed to 700KB by gzip)
What's included to the file:
- Site structure (needed)
- store states (containing ALL slides/decks --> that's a large part of the document)
- rendered HTML contains some data that is also in the store (like users, slides, decks, ...) --> duplicated data in the response
- users are included several times in different stores (each time with their base64 user picture, that is a large part of the user) --> duplicated data in the response
- presentationStore and deckViewStore contain all slides of a deck + extra data --> duplicated data in the response - think of soerens deck, that has 800 slides --> these are included at least twice!
Possible improvements
Main Showstoppers:
- waiting for upstream (service) requests
- componentUpdate events might occur very often and trigger (possibly unneeded) rerenderings of the component
- there is no server-side cache for upstream requests to services - data will be requested again and again and again as SSR won't keep any states/contexts over time --> adding cache headers to responses from services will have no impact
Options to improve the situation:
- load only a part of the deck/slides instead of ALL of it (this is by far the largest part of the file) - e.g. always load the "next" 10 slides (5 before and 5 after the currently displayed one) and to fetch more if needed + removing old slides from the store/DOM in order to keep it small and responsive
- decreasing the initial deck load by adding/using a minimal deck-service call
- there are already https://deckservice.experimental.slidewiki.org/documentation#!/deck/getDeckId (deck metadata) and https://deckservice.experimental.slidewiki.org/documentation#!/slide/getSlideId (data of first slide)
- locate and replace the initial deckservice-call (currently: load all slides of a deck) with the two above minimal deck-service calls
- try to reuse information that is already contained in other stores, instead of downloading and saving them a second time to a different store
- save user pictures as actual pictures to the file-service instead of base64, so they are handled by the browser instead of included into the SSR response
- execute as many requests as possible in parallel and try to optimise response times (at the services) or request smaller amounts of data at all
- try to only update (rerender) components once, instead of several times - see https://marmelab.com/blog/2017/02/06/react-is-slow-react-is-fast.html
- it's possible to use React component caching (instead of rerendering them for each request), but this non trivial to implement, requires a lib that hot patches react itself on execution time and needs to be specified for each component separately - see https://www.npmjs.com/package/react-ssr-optimization
- try to load data on user events, instead of prefilling stores/DOM (e.g. request data in case the user opens a tab, instead of downloading that data as the user visits the page)
Fetchr Insights
- cache responses from fetcher (slidewiki-platform --> browser) by using cache directives. This will not improve SSR timings, but may improve requests from the browser to slidewiki-platform. See https://github.com/yahoo/fetchr#service-metadata . I think this is only useful if we also do:
- restrict context variables to have smaller/more simple requests that are better cachible, see https://github.com/yahoo/fetchr#service-metadata
- there is no server-side cache for upstream requests to services - data will be requested again and again and again as SSR won't keep any states/contexts over time --> adding cache headers to responses from services will have no impact
- Requesting a service directly takes only a little amount of time (e.g. forking a deck: 300ms). Doing the same thing through slidewiki-platform with the full fetchr, encryption, compression and transformation workflow takes significantly more time (about 6-9 secs)
- slidewiki-platform server side is a bottleneck to all service → we don't know if this is responsible for the time increase
- slidewki-platform is doing some transformations at some services
- the full cycle via slidewiki-platform inclused a lot more ecnryption/decryptiond and compression/decompression steps
- → We need to somehow measure timings of routes and CPU load of services/containers (use cadvisor + store data, use NewRelic)
--> this needs to be implemented for each slidewiki-platform service and method (if it's useful!)
Further insights from looking into slidewiki-platform:
- in case I change from one slide to another one, the whole deck is requested and downloaded again in order to display one slide (via service presentation.js, read method)
- only one slide should be requested instead of all + this data is currently available in a store (why requesting it another time?
all libs in defaultHTMLLayout.js are loaded in order - try to use "async" or "defer" to load libs (if this is possible!)
Improvements for MongoDB queries:
Indexes! Adding indexes to collections, greatly improves the search time for the correct documents but increases memory usage.
See slide 9 in https://docs.google.com/presentation/d/1-5pBwpmC4nghs8FFf8fpLz1BIgrNbgZBTL40eVXRbQM/edit#slide=id.g110a6bec5f_0_27 for general information about MongoDB and Indexes.
We have to check performance of each service and the database, but Kurts feeling is that other topics (which are already identified as problems) should be done before digging into indexes.
-> SWIK-1609 is the parent ticket and contains basic assistance