Based on presentation (general-optimization.pdf) on optimization by Ali Khalili during Hackathon V3.0
|
|
|
|---|---|---|
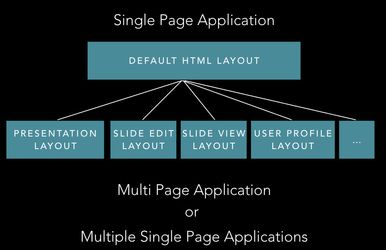

Splitting layout
- multi-page application → in components/defaultHTMLlayout.js → based on URL load certain libraries (e.g. CKeditor for visiting URL /edit)
- we can have a generic layout inherited by other layout if needed (e.g. ui intl libraries or shim libs need to be reused in most of the other layouts).
- multiple single-page applications → standalone aplication. E.g. presentation layout (reveal.js is large), slide edit layout (CKeditor = 600kb, Latex_ams.. libary = 500kb, ), slide view, user profile layout, etc... In practice → separate github repot + is separate application → has own server.js/client.js/etc...
- multiple single-page applications → Better for scalability
- multi-page application → better for user loading (only load libraries when necessary, based on URL/page visit)
- Presentation mode - standalone/multiple single-page applications - do not need to load fluxible, etc.. (single page application). Needs to load reveal.js and Latex_ams.. libary and maybe some SVG/diagram libraries, semantic UI)
- exam mode (
- user profile
- slide edit layout → multipage → part of platform → on loading /edit also load ckeditor, Latex_ams.. libary and some SVG/diagram libraries
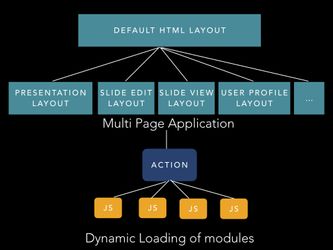
Dynamic/lazy loading of modules → action → select j.s. file . use ES6 require.ensure - Darya Tarasowa - interesting in applying - related to multi-language UI.
- Is complicated
- Is good for when other developers want to work on something → we give bundle with component, action, js. files/libraries
Optimize Current libraries (see webpack visualiser: https://platform.experimental.slidewiki.org/public/js/stats.html) → check npm packages
- replace with another library (e.g. lodash is using 20% of our vendor.bundle.js code, maybe it can be replaced by a simpler one), or
- use own functions
Analysis/results in #performance Slack channel:
Roy Meissner [5:14 PM]
I'm currently digging through the server-side rendering part:
The page is initially ALWAYS rendered server-side. This means:
* the complete react+flux flow is executed
* all needed actions are executed (waiting for responses, adding results to stores, rerendering, ...)
* the page is rendered and gets serialized to a valid html document (that is delivered to the client).
* listed libs in the DefaultHTMLTemplate are downloaded at the browser (not at as of the server side rendering)
For https://slidewiki.org/deck/82 , this takes about 25.86s and the file is about 5MB large (compressed to 700KB by gzip).
What's included to the file:
* Site structure (needed)
* store states (containing ALL slides/decks --> that's a large part of the document)
* Renderd HTML contains some data that is also in the store (like users, slides, decks, ...) --> duplicated data in the response
* Users are included several times in different stores (each time with their base64 user picture, that is a large part of the user) --> duplicated data in the response
* PresentationStore and DeckViewStore contain all slides of a deck + extra data --> duplicated data in the response - think of soerens deck, that has 800 slides --> these are included at least twice!
Options to improve the situation:
* load only a part of the deck/slides instead of ALL of it (this is by far the largest part of the file)
* try to reuse information that is already contained in other stores, instead of downloading and saving them a secend time to a different store
* save user pictures as actual pictures to the file-service instead of base64
* There seems (!!!) to be no server-side cache for the rendering --> All services are requested again and again for the same data, but json responses do not contain an etag anyway. Thus it's not possible to cache anything --> think of adding etags (or better cache directives) to json responses and look for a way to cache server-side
Questions:
* is server-side rendering ALWAYS mandatory? Shouldn't it only render server-side, in case the client can't execute JS? (edited)
Roy Meissner [5:20 PM]
In case you want to have a look at such a file yourself ( it's the relatively small deck "Got the tech"): (edited)
Klaas [5:40 PM]
Nice analysis!
Judging from the file sizes, decreasing the initial deck load by adding/using a minimal deck-service call would solve much of the performance problems:
* load only a part of the deck/slides instead of ALL of it (this is by far the largest part of the file)
There is already https://deckservice.experimental.slidewiki.org/documentation#!/deck/getDeckId (deck metadata) and https://deckservice.experimental.slidewiki.org/documentation#!/slide/getSlideId (data of first slide) with which we could have a minimal load.
So then we have to locate and replace the initial deckservice-call (currently: load all slides of a deck) with the two above minimal deck-service calls.
Or am I missing something here? (edited)
----- Today August 29th, 2017 -----
Roy Meissner [3:44 PM]
Sounds good to me. It might be best to always load the "next" 10 slides (5 before and 5 after the currently displayed one) and to fetch more if needed + removing old slides from the store/DOM in order to keep it small and responsive.
Roy Meissner [4:17 PM]
Insights from looking into fetchr:
* It's possible to cache responses from fetcher (slidewiki-platform --> browser) by using cache directives (like "expire"). This will not improve SSR timings, but may improve requests from the browser to slidewiki-platform. See https://github.com/yahoo/fetchr#service-metadata . I think this is only useful if we also do:
* Restrict context variables to have smaller/more simple requests that are better cachable, see https://github.com/yahoo/fetchr#service-metadata
--> this needs to be implemented for each slidewiki-platform service and method (if it's useful!)
Further insights from looking into server side rendering (SSR) - main show stoppers:
* waiting for upstream (service) requests --> execute as many requests as possible in parallel and try to optimise response times (at the services) or request smaller amounts of data at all (like already mentioned deck/slide requests)
* try to only update (rerender) components once, instead of several times - include logs in the render methods to see how many times a component is rendered
* It's possible to use React component caching (instead of rerendering them for each request), but this non trivial to implement, requires a lib that hot patches react itself on execution time and needs to be specified for each component separately.
* There is no server-side cache for upstream requests to services - data will be requested again and again and again as SSR won't keep any states/contexts over time --> adding cache headers to responses from services will have no impact
Further insights from looking into slidewiki-platform:
* in case I change from one slide to another one, the whole deck is requested and downloaded again in order to display one slide (via service presentation.js, read method) --> only one slide should be requested instead of all + this data is currently available in a store (why requesting it another time?) (keep in mind that you're about to change that!)